
Fixing flaky Playwright visual regression tests
We utilise visual regression tests in our pipelines to give us confidence that the code we’re about to ship hasn’t unexpectedly changed anything visually. We achieve this by using Playwright’s screenshot functionality to capture the page and upload it to Percy. We opted for Percy instead of Playwright’s built in visual comparisons because we like having a simple and intuitive UI to review the difference. If there’s a difference between the screenshot on main and our proposed changes, we get a view like this which we can review and approve if we’re happy:
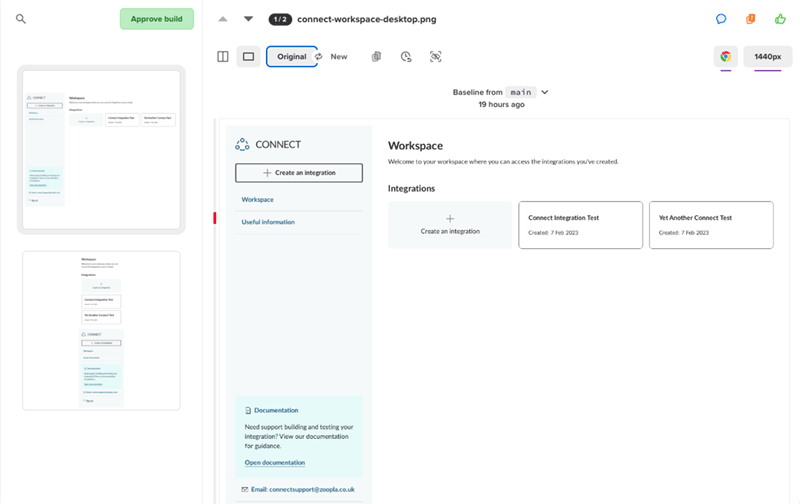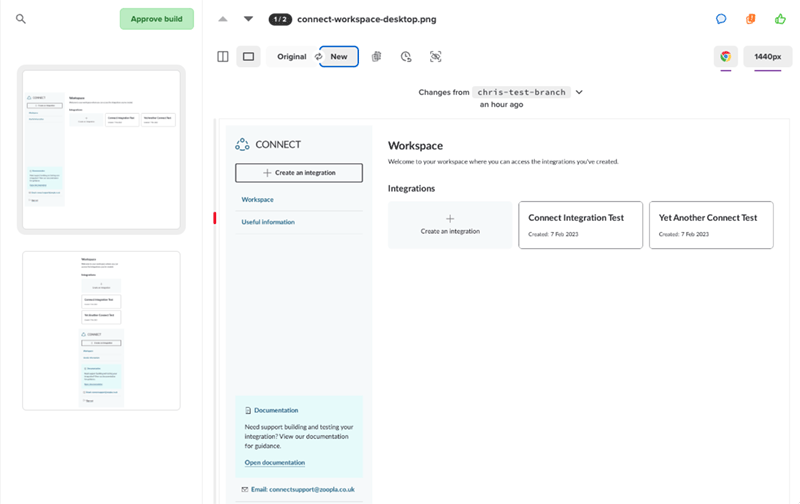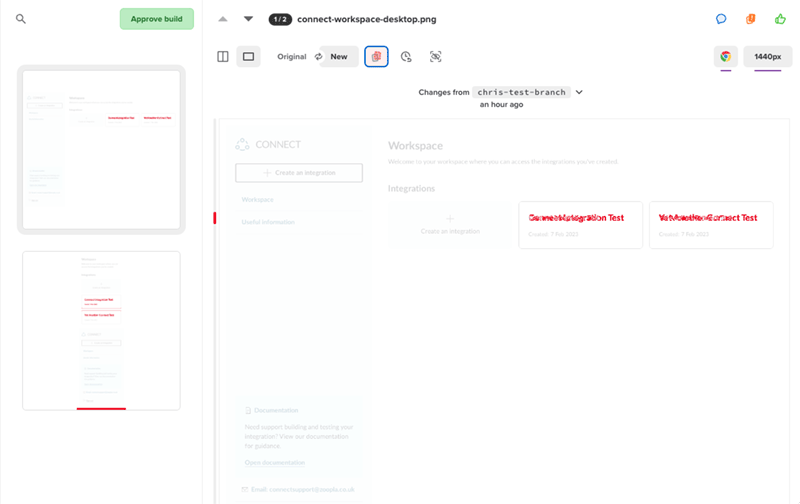
This has proved to be a super valuable tool in our testing arsenal. However visual testing can be notoriously tricky to get stable. This is because code that runs client-side often isn’t straightforward - we’re battling with asynchronously firing scripts, third party scripts behaving inconsistently, loading states, animations, modals - the list is endless. This complexity can lead to instability and “flaky” tests.
For the tests to give us confidence in our changes, they need to be stable. If our engineers don't trust the results, they might disregard them, and blindly approve screenshots. This would defeat the purpose of having them running in the pipeline.
On Alto, our estate agent software for property management, we currently capture around 200 screenshots and this list will grow over time. While most were stable, we found there were a handful which were flaky. We recently spent time on these tests to make them stable and rebuild trust in our visual tests.
Mock, mock, mock
This one is a bit of a given but a good starting point - don’t rely on data coming from a database/service for your visual tests. Your application needs to be visually consistent for the screenshots to be worthwhile so we want a consistent dataset.
We use Mock Service Worker to mock:
- Endpoint responses
- User profiles
- Feature flags
We opted for Mock Service Worker because we wanted to use the same mocks across our entire stack, however Playwright has built in API mocking too which can be used for the same purpose.
On top of data mocks, consider what browser functionality you’re relying on. For example, for the date (we use this util to mock it).
Utilise waits
Make use of Playwright’s waitFor before capturing the screenshot. The default state for waitFor is visible so in this example, we know the heading is visible before capturing our screenshot:
await page.getByRole('heading', { name: 'My Heading' }).waitFor();
await page.screenshot({
path: 'myapp/foo-bar.png',
fullPage: true,
});If something asynchronous needs to run before taking the screenshot, you can wait for its visual state to change. In the below example, we want to ensure the loading spinner is hidden from view and our image is visible before our screenshot. This ensures the page is in the right state before capturing:
// Wait for loading spinner to hidden
await page.getByTestId('loading-spinner').waitFor({
state: 'hidden',
});
// Wait for image to be visible
await page.getByAltText('My Image').waitFor();
await page.screenshot({
path: 'myapp/foo-bar.png',
fullPage: true,
});Capture what you need
We noticed instability on smaller device sizes when content displayed in a modal. It would open at slightly different places. Take the below example:
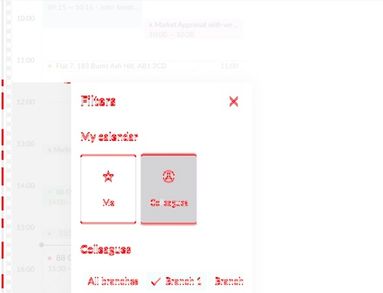
This won’t get caught by our sensitivity threshold because all of the elements in the modal are in a slightly different place. We asked ourselves, what are we trying to test here? We’d already captured the page before the modal click so what’s valuable is the content of the modal. Our approach was to just screenshot the modal instead:

await page.getByLabel('My element').screenshot({
path: 'myapp/foo-bar.png',
});This approach has been stable and still captures enough to give us confidence in our changes.
Hide/block third parties
Third party scripts can be unpredictable and difficult to test. They fire off at different points, delay page loads and interactivity. Going back to our “capture what you need approach” - if we have an embedded third party map which loads in an iframe - we can’t confidently wait for the contents to load because the code runs in its own document and is also susceptible to any change in selectors, styles, functionality etc. It’s also not our application code. In this instance we value trust in our pipelines over needing to capture this piece of the page so we can choose to mask it:
await page.screenshot({
path: 'myapp/foo-bar.png',
fullPage: true,
mask: page.locator('#map'),
});
We can still see the space it occupies but we don’t get the instability which comes with capturing exactly how the map looks.
Another approach is to block the third party script from firing. If you have analytics scripts, tag managers - anything that doesn’t belong in a visual test, block it!
// Block Google maps before visiting page
await page.route(/googletagmanager.com/, route => route.abort());
await page.goto('https://yourapplication.com');Disable animations
Animations such as transitions can be unpredictable to test against, fortunately we can pass animations: 'disabled' to our screenshot and “finite animations are fast-forwarded to completion, so they'll fire transitionend event. Infinite animations are cancelled to initial state, and then played over after the screenshot.” (source). Easy!
Chrome full page screenshot bug
We noticed some strange behaviour on some of our full page screenshots where the image would get clipped:

We concluded it was most likely due to this Chromium bug which sadly is marked as “Won’t fix”. We used the approach of scrolling the length of the page before taking the screenshot (as suggested here) for screenshots with the clipping problem:
// Utility method
export const scrollFullPage = async (page: Page) => {
await page.evaluate(async () => {
await new Promise((resolve) => {
let totalHeight = 0;
const distance = 100;
const timer = setInterval(() => {
const scrollHeight = document.body.scrollHeight;
window.scrollBy(0, distance);
totalHeight += distance;
if (totalHeight >= scrollHeight) {
clearInterval(timer);
resolve(true);
}
}, 100);
});
});
};
// Scroll page first
await scrollFullpage(page);
// Then take screenshot
await page.screenshot({
path: 'myapp/foo-bar.png',
fullPage: true,
});This approach, while still feels unnecessary, has yielded consistent results.
Building a stability culture
Once we were confident in our test stability, we needed to keep it that way so we imposed a zero flake policy. This means, if a test is flaky visual test is spotted, it needs to either be fixed right away or tagged with fixme until an engineer can look into it. This helps us maintain a consistently stable suite and ensures our engineers always trust the results of the regression test. We used this strategy, because to us not having the test is more valuable than the loss of confidence a flaky test introduces.
Conclusion
These are just a few small ways we’ve kept our visual tests stable. Visual regression is challenging to get right, there’s a lot of edge cases and it’s easy for them to become unstable. However once your suite performs consistently, it gives engineers the confidence to make changes and know exactly how it’s going to look for the customer - which is the whole point of having them in the first place.
Image source
- Post image by Zalfa Imani on Unsplash